PyTorch的自动混合精度
“自动混合精度”(Auto Mixed Precision,AMP)指的是在进行Tensor运算操作时,根据不同的操作符自动将数据类型进行精度转换。
PyTorch通过torch.amp来支持这一功能。
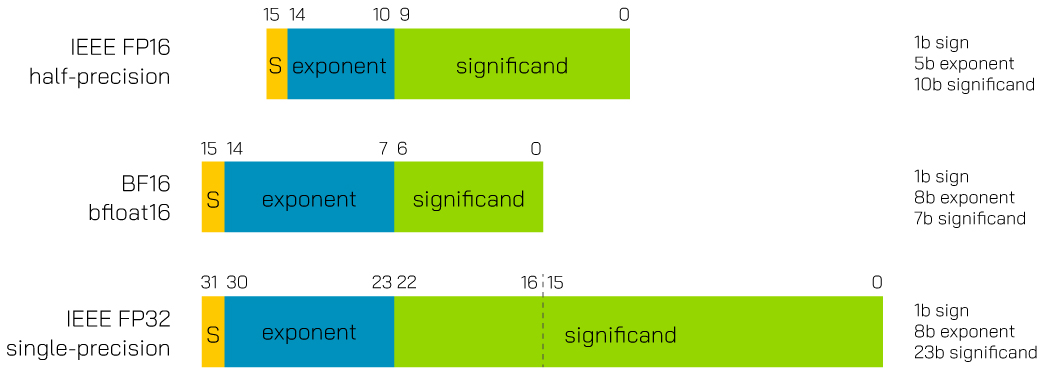
AMP涉及多种不同精度的数据类型。其中,float16、float32分别为标准的16位和32位浮点数,而bfloat16则是谷歌开发的新格式,brain float number。bfloat16相比于float16,增加了指数位,减少了小数位,通过牺牲精细度换取了更大数值范围。这几种数据类型的区别如下图所示。
PyTorch中默认数据类型是float32,但有些运算中,将其转换为16位可以既保障运算准确,又节省空间和时间。AMP的作用就是自动判断适合的运算符,并将其输入数据类型做转换。
自动转换(amp.autocast)
使用AMP只需将想要进行混合精度的代码区域用torch.amp.autocast(或别名torch.autocast)包括即可。autocast可以用作上下文管理器,如下所示:
# Enables autocasting for the forward pass (model + loss)
with torch.autocast(device_type="cuda"):
output = model(input)
loss = loss_fn(output, target)
# Exits the context manager before backward()
loss.backward()
也可以作为函数的修饰器,如下所示:
class AutocastModel(nn.Module):
...
@torch.autocast(device_type="cuda")
def forward(self, input):
...
torch.amp.autocast(device_type, dtype=None, enabled=True, cache_enabled=True)的几个参数中,前两个主要用于确定自动转换的目标类型。如果指定了dtype,就以它为准;否则会根据device_type为”cpu”还是”cuda”来将dtype定为”bfloat16”还是”float16”。通过另外两个参数可以打开或关闭自动转换,便于测试开或关的效果。
从上面例子可以看出,autocast区域中应该包含模型网络的前向传递和损失计算,而不应包含后向传递。这是因为后向传递的运算符会和其相应前向传递运算符保持一致的数据类型,不再适用自动转换。
另外,autocast代码区的进入数据可以是任意类型,从中出来的数据类型则可能和原来不同(一般会是dtype指定的float16或bfloat16)。运算结果在区域外和其他数据进行再计算时,或许需要手动转换为其他类型,以防类型不匹配的异常。
梯度缩放(amp.GradScaler)
在模型训练中,autocast通常和梯度缩放(Gradient Scaling)结合起来使用。这是因为,前向传递中数据如果被转换为float16位,那么后向传递时的产生的梯度也将用float16表示。如果梯度值太小,float16就会存成0,造成信息损失。为了让梯度值变大,就需要把前向传递得到的损失(loss)值也放大,这正是amp.GradScaler的用途。
所以采用AMP的训练代码通常会是下面这样的形式。
# Creates a GradScaler once at the beginning of training.
scaler = GradScaler()
for epoch in epochs:
for input, target in data:
optimizer.zero_grad()
with autocast(device_type='cuda', dtype=torch.float16):
output = model(input)
loss = loss_fn(output, target)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
可以看到, scaler.scale(loss).backward()这一句中loss先被缩放然后才做反向传播计算梯度,而且scaler.step(optimizer)代替了optimizer.step(),前者内部会按需来进行反向缩放并调用后者。
scaler.step(optimizer)执行之前,optimizer中的梯度还是放大后的。这时如果有一些操作需要对未放大的原梯度进行,例如梯度截断(Gradient clipping),就应该先显式调用scaler.unscale_(optimizer)反向缩放。
关于梯度缩放如何配合其他梯度相关操作,包括梯度累加(Gradient accumulation)、梯度惩罚(Gradient penalty)等,可以参见这个示例页面。PyTorch官网的另一个文档也提供了更多参考信息。
如果想要说些什么,欢迎发邮件给我。