3D视频技术概论
这篇文章属于《恰同学少年》系列,写于2010年。
随着生产生活的发展和技术的进步,3D视频越来越进入人们的眼界。相对于一般的2D视频来说,3D视频能够提供更丰富的信息、更好的观看体验,因此将成为未来视频显示的主流。本文试对3D视频相关技术做一个概要性的总论,可以作为该领域研究工作的入门引导。
3D技术的概念和应用
我们所感知到的世界是三维(3 dimension,即3D)的,所谓的3D技术,笼统的说就是试图重建人的真实三维感觉的技术。
3D技术包括许多方面。比如3D建模、3D动画制作、3D视频获取与显示,以及相关的3D数据编码、储存、传输技术;等等。作为改善人类对信息的记录和感知的一种手段,3D技术的应用也将逐渐普及。3D模型和动画在建筑、制造领域和以及娱乐行业已经获得了广泛的应用。3D视频又可称为立体视频,因其更接近实际的信息和观感而优于传统平面视频(并终将取代之)。就影视行业来说,《阿凡达》的上映已经引领电影继有声和彩色之后进入了一个全新的时代——3D时代。立体视频的另一个典型应用是3DTV系统。3DTV就是在现有的电视系统基础上,将所有平面的电视图像以立体视频取代,给人更真实的电视观看体验。进一步有人提出了“现实广播系统”(realistic broadcasting system,参见[3DVideoPro]),如下:
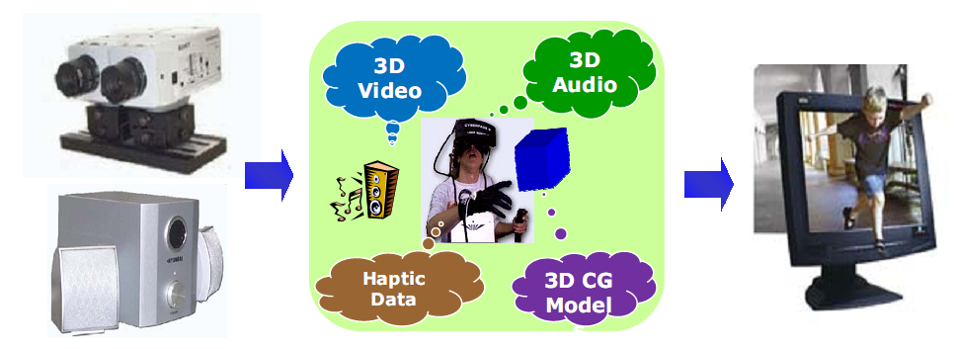
其中通过混合3D视频、3D音频(即通常所说的立体声),辅以3D模型以及触觉数据,让“观众”得以感受到完整的现实世界。该设想中,3D音频和模型已经是较为成熟的技术,而3D视频是目前研究的热点。
除了以上提及的领域,立体视频或图像在无人机导航、太空探索、医学显微和手术等计算机视觉起作用的地方都将有应用前景。本文以下就主要论述立体视频技术。
立体视频及其显示
人在观看实际场景时,三维物体在左右眼中投影成像分别得到左右视图,由于双眼观看的视角不同,其对应视图也不同,表现为对应于同一个实际空间点的投影在水平坐标上有差异,其中的差异值称为视差。视差值的大小,与该实际空间点与观看者的距离有关,距离越近,视差越大;距离越远,则视差越小。正是由于视差的存在,人在大脑中才形成了深度信息和立体感。传统的平面视频图像内容只能向观看者提供单视角的图像,左右眼接收到的是相同的视图,这与实际场景的观看是不一致的,因此传统的平面内容无法呈现场景的深度感。
而立体视频技术的出现正是为了弥补这一缺憾。立体视频技术通过投射不同视角的视频图像,使观看者的左右眼能够捕获不同视角的视觉信息,对应的视差信息将在大脑中形成场景的深度感,从而再现实际观看时的立体感。
由以上原理分析可知,立体视频的关键是能够让观看者双眼接收到不同的视觉信息。因此除了视频本身要包含给双眼的不同内容,还需要适当的显示方式配合来确保将不同的内容提供给不同的眼睛。目前在市场上,比较成熟的立体视频内容显示方式包括:需要佩戴特殊眼镜的双目立体显示技术、能够裸眼观看的多视角立体显示技术。
双目立体视频显示技术需要观看者佩戴特殊制作的眼镜,来控制进入人眼的视图。根据显示内容的不同格式区分,常用的双目立体显示技术有红绿显示、偏振显示、遮光显示。
多视角立体显示技术,通过在平面显示器前端配置光栅来改变光线的投射方向,不同的视图在空间中形成投影视锥,观看者在观看过程中,双眼位于不同视锥中,接收不同视角的图像,获得立体的视觉效果。
值得注意的是,多视角技术由于在显示器端已经控制了双眼视图的分离,故不再要求观看者佩戴任何辅助设施,即能够裸眼观看。目前市场上多视角立体显示器按照光栅的类型不同,可以分为狭缝光栅多视角立体显示器和棱镜光栅多视角立体显示器。
考虑到人观看的便利性,不需佩戴眼镜的裸眼立体显示技术应该是更好的选择。
立体视频内容生成
立体视频内容包含了多个视角的视觉信息,生成立体视频的技术可以分为三类:平面视频转立体视频(2D转3D)、多摄像机立体拍摄(立体采集)以及立体动画生成。
一直以来,立体视频内容的匮乏是立体视频技术推广的瓶颈。考虑市场上平面视频内容的迅速增长,通过平面视频转立体视频技术,可以方便快速地得到立体视频内容。该技术通过分析平面视频,半自动/全自动地得到场景的深度信息,并通过对原视频图像进行变形等操作生成其他视角的视图,最终合成显示即为立体视频。
多摄像机立体拍摄技术随着摄像硬件设备的发展而逐渐成熟。双目/多目拍摄,能够同时获取场景在多个视角下的视图,最后直接合成得到立体视频内容。立体拍摄技术得到的内容视觉效果较高,但是需要解决数据同步、大量数据的保存与传输等问题。
立体动画技术是目前成熟商用的立体视频生成技术。该技术的视频内容完全由计算机虚拟制造。一般先使用3ds max等软件制作动画场景的三维模型,然后在场景中摆放虚拟的摄像机组,进行投影渲染,得到不同视角的投影视图,最后合成得到立体视频内容。目前,市场已经出现了多部3D动画电影,如著名的《怪兽大战外星人》、《冰河世纪III》。
由于立体动画制作并非面向实际场景的立体视频内容生成技术,故本文对其不再深入介绍。下面详细说明前两种,即2D转3D技术和立体采集技术。
2D转3D
2D转3D即通过分析2D视频得到各帧图像的深度图,从而将其转化为立体视频。由于只有二维的信息是不可能完全再现三维场景的,因此只能靠推测和估计,尽量得到好的立体视觉效果。
2D转3D的关键是深度图的生成。一帧平面图像的深度图即为每一个像素赋予深度值。一般来说为了渲染出立体效果,不需要连续的深度值,只需几个深度阶,能体现出物体的前后即可。得到一帧图像的深度图,首先要对图像进行分割,分析出图像中的背景区域和前景物体,然后为背景和物体分别赋给较小或较大的深度值(一般认为物体离摄像机越近则深度值越大)。
2D转3D技术分为半自动转换和全自动转换,其区分主要在于深度图的生成上。全自动算法可以完全在人不参与的情况下,将一幅图像根据内容分割不同区域,自动为各区域赋予适当的深度值,得到深度图。但可以想象,软件算法的分析肯定有与实际不符之处,因此有时得到的深度图效果很差,这种全自动算法的应用是有限的。半自动2D/3D转换中由人工帮助分割物体及赋深度值,加入了人的经验和认知,结果显然更加准确,但也增加了劳动和时间花费。考虑到最终效果的需要,目前市场上2D转3D生成的立体视频基本上都是在人工参与下进行的半自动转换。
在半自动2D转3D时,一般只选取视频中的关键帧进行人工操作,对其他非关键帧则使用特定算法由程序完成深度图的传播(depth propagation)。
得到2D视频的深度图之后,通过基于深度图的渲染(DIBR)算法可以得到用于立体显示的3D视频。可以渲染得到给左右眼的双目立体视频,也可以渲染得到多视角的立体视频,用于不同的显示器。
立体采集
立体采集是直接拍摄得到立体视频的技术。这种技术是对传统摄像过程的改造,试图在拍摄时就获得立体信息。按照相机原理的不同,立体采集有多种形式。
前边提到的多相机拍摄是通过增加相机数量来模拟人双眼的观看,可以直接得到不同视角的图像,从而用于立体显示。但这种形式在采集时需要多相机的校准和同步,而且得到的数据量也成倍增加,
深图相机是在传统相机拍摄的基础上同时获取场景中的深度值。这虽然只有一个视角,但由于已经采集得到了深度图,所以可通过渲染获得立体视频内容。深度相机利用Time of Flight(TOF)原理来测量镜头到物体的距离,以此来计算深度图并储存下来。此外,一般的深度相机还会输出其他的信息来帮助后续渲染过程。
相关技术研究
对2D转3D技术中的深度图求取,研究者提出了多种方法。
半自动2D转3D中,由人工进行关键帧的物体分割和深度赋值。这里为了进一步减少操作,有人提出了基于机器学习的方法[2002 SPIE]。采用机器学习算法(MLA),仅需要人工训练少量的点,则MLA对其他点自动赋深度值,以得到整个关键帧的深度图(关键帧可以人工定位,也可以通过计算跃变由程序完成);对于关键帧之间的Depth Tweening,也可引入MLA:对每一个中间帧,分别用其前后两个关键帧的MLA计算其深度z1、z2,然后按权平均得到z 。这样可以减少半自动中的人力花费。
由关键帧的深度图外推出其他帧的深度图还可采用“双边滤波”(Bilateral Filtering)的方法——根据上一帧(如关键帧)及其已知的深度图来计算本帧各像素的深度,采用位置距离和颜色两种因素来判断并加权合成。这种方法中进一步通过基于块的运动补偿来消除误差。
全自动2D转3D中,对平面图像的物体区域分割(Object Segmentation)和深度计算(Depth Calculation)都要由程序来完成。有研究者提出基于KLT追踪的方法[2008 VIE]。适当选取KLT特征点,计算它们随帧序列的运动,运动相似的特征点被认为属于同一个物体(采用Flood Fill算法),由此来进行物体分割(分割出的物体轮廓还可通过Snake算法进一步精细化)。分割后的物体深度计算也是基于运动的。简单来说,运动快的认为离镜头近,便赋予其较大的深度值;当然,这种深度计算结果可以通过其它信息进行校正,如遮挡情况。
还有学者提出骨架线追踪的方法来完成半自动转换中的深度传播[2009 3DTV]。对关键帧进行手工物体分割后,先得到各物体的骨架线(利用grass fire算法),然后只需对这些骨架线而非整个物体进行追踪,就可以方便得到其他非关键帧的深度图。由于骨架线含有少的多地数据,因此追踪起来不必使用复杂的KLT算法,只需用基于光流运动矢量方法即可。这减少了运算复杂性。
一般来说,只要得到2D视频的深度图,就有成熟的渲染算法(DIBR)来生成用于显示的3D视频。需要提到的是,最终的3D视频是与一定的显示/观看方式相联系的。为一种观看条件准备的“stereo pair”不一定适合另一种,因此要针对特定的显示(观看)条件生成3D视频。反过来思考,其实我们只要提供针对特定显示条件的3D数据即可,不一定非要求深度图。有的研究就另辟蹊径,不去求深度图而直接得到一种“视差”(“disparities”)信息,用于立体显示[2009 ICCV]。
以上主要对2D转3D技术的研究做了介绍。在立体采集领域面临的就不仅是算法的问题,而要涉及硬件物理、通信、同步和控制、抗扰等诸多因素,这里不再深究。
结语
电影《阿凡达》的上映,让3D技术与人们的生活近了一步。随着科技和工艺的发展,未来生活中3D视频将如现在的2D视频一样无处不在。为当前的3D化浪潮作贡献将是令人兴奋而有意义的学术方向。当然,入门以后,3D视频技术的研究需要比本文多得多的知识。就算法而言,就需要扎实的数学知识和编程实现的能力,更勿论立体采集和显示涉及的硬件知识和物理知识。此外,作为一种新的数字媒体,3D视频也需要与其适应的编解码、压缩、储存、检索等传统的信息处理。这都需要进一步探索。
3D——增加了新的维度,也带来了新的挑战和机遇。
参考阅读
[3DVideoPro] 3D Video Processing for Realistic Broadcasting System
[2002 SPIE] Rapid 2D-to-3D conversion
[2006 3DTV] A Modular Scheme for 2D-3D Conversion of TV BroadCast
[2007 IETC] Improved depth propagation for 2D to 3D video conversion using key-frames
[2008 3DTV] A Novel Method for Semi-automatic 2D to 3D Video Conversion
[2008 VIE] An Efficient Method for Automatic Stereoscopic Conversion
[2009 3DTV] An efficient 2D to 3D video conversion method based on skeleton line tracking
[2009 ICCV]Semi-automatic Stereo Extraction from Video Footage
如果想要说些什么,欢迎发邮件给我。